How to create custom indices based on Kubernetes metadata using fluentd?
In the previous articles, we learned about setting Fluentd on Kubernetes with the default setup config. Now in this article, we will learn how to create custom indices using Fluentd based on Kubernetes metadata and tweaking an EFK stack on Kubernetes.
Here, I will be using the Kubernetes metadata plugin to add metadata to the log. This plugin is already installed in the Docker image (fluent/fluentd-kubernetes-daemonset:v1.1-debian-elasticsearch), or you can install it using “gem install fluent-plugin-kubernetes_metadata_filter” into your Fluent docker file. Use the filter in Fluentd config value to add metadata to the log.
# we use kubernetes metadata plugin to add metadatas to the log
<filter kubernetes.**>
@type kubernetes_metadata
</filter>Here, our source part is the same as we used in setting Fluentd on Kubernetes with the default setup config. I will customize the matching part in the default config and create a custom index using Kubernetes metadata. So here we are creating an index based on pod name metadata. The required changes are below into the matching part:
# we send the logs to Elasticsearch
<match kubernetes.**>
@type elasticsearch_dynamic
@log_level info
include_tag_key true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER']}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD']}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
ssl_verify "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERIFY'] || 'true'}"
reload_connections true
logstash_format true
logstash_prefix ${record['kubernetes']['pod_name']}
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever true
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 32
overflow_action block
</buffer>
</match>I will use Kubernetes metadata in logstash_prefix “${record[‘kubernetes’][‘pod_name’]}” to create an index with the pod name. You can also create an index with any Kubernetes metadata ( like namespace & deployment ). And here, you can tweak some configuration for logging data to ES as per your need. Suppose I don’t want to send some unwanted logs to ES like Fluentd, Kube-system or other namespace containers’ logs, so you can add these lines before the Elasticsearch output:
<match kubernetes.var.log.containers.**kube-logging**.log>
@type null
</match>
<match kubernetes.var.log.containers.**kube-system**.log>
@type null
</match>
<match kubernetes.var.log.containers.**monitoring**.log>
@type null
</match>
<match kubernetes.var.log.containers.**infra**.log>
@type null
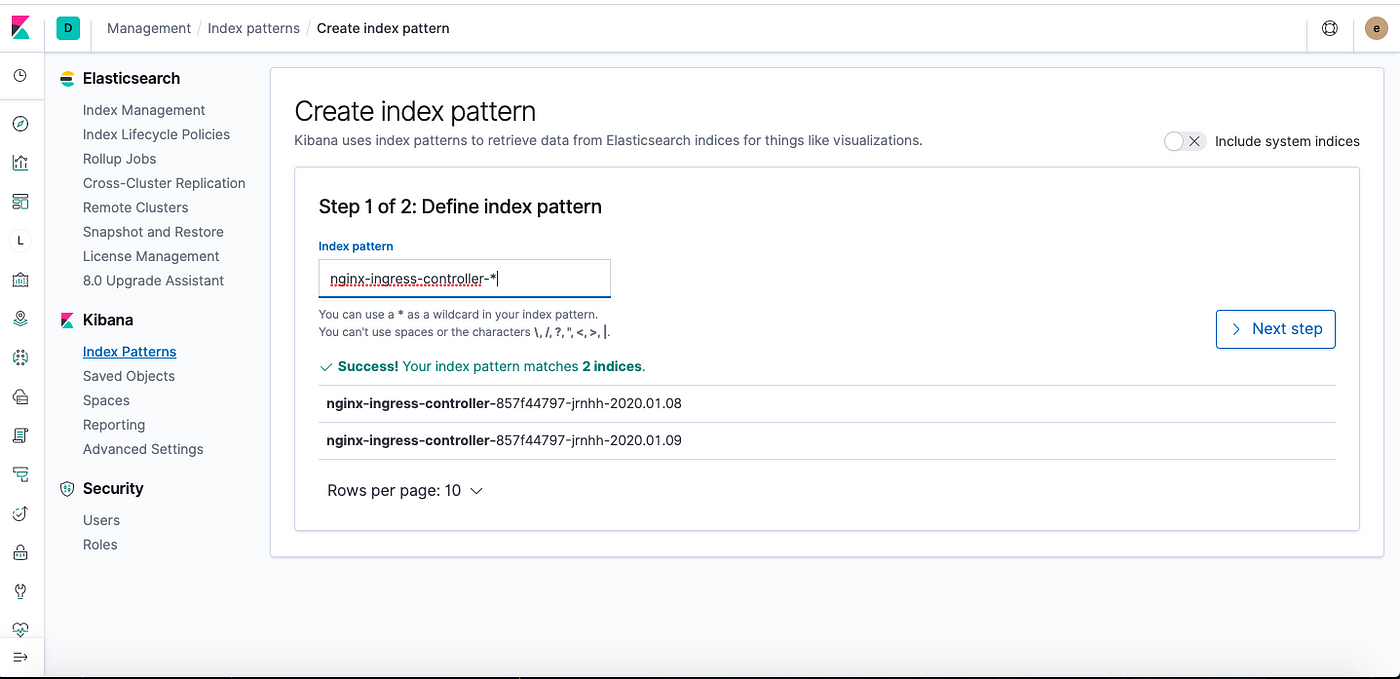
</match>Here, we have the final Kube-manifest config map, we just need to run it and apply the changes to the k8s cluster and rolling deploy the existing Fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
namespace: infra
data:
fluent.conf: |
<match fluent.**>
# this tells fluentd to not output its log on stdout
@type null
</match>
# here we read the logs from Docker's containers and parse them
<source>
@type tail
path /var/log/containers/*.log
pos_file /var/log/containers.log.pos
tag kubernetes.*
read_from_head true
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
# we use kubernetes metadata plugin to add metadatas to the log
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match kubernetes.var.log.containers.**kube-logging**.log>
@type null
</match>
<match kubernetes.var.log.containers.**kube-system**.log>
@type null
</match>
<match kubernetes.var.log.containers.**monitoring**.log>
@type null
</match>
<match kubernetes.var.log.containers.**infra**.log>
@type null
</match>
# we send the logs to Elasticsearch
<match kubernetes.**>
@type elasticsearch_dynamic
@log_level info
include_tag_key true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER']}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD']}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
ssl_verify "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERIFY'] || 'true'}"
reload_connections true
logstash_format true
logstash_prefix ${record['kubernetes']['pod_name']}
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever true
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 32
overflow_action block
</buffer>
</match>$ kubectl apply -f fluentd-config-map-custome-index.yamlAfter applying the changes, now we have indices with pod names which can be seen in ES and Kibana.
I hope this blog was useful to you. Looking forward to claps and suggestions. For any queries, feel free to comment.